
Быстрые темпы развития искусственного интеллекта (ИИ) породили опасения о том, что роботы могут действовать неэтично или могут выбрать решение, причиняющее вред человеку. Некоторые люди выступают за запреты в исследованиях по робототехнике, другие призывают к проведению дополнительных исследований, чтобы понять, как могут быть ограничены возможности ИИ. Но как роботы научатся этическому поведению, если у них нет руководства пользователя о том, как быть человеком?
Исследователи Марк Ридл и Брент Харрисон из Школы интерактивных вычислений Технологического института Джорджии считают, что ответ на этот вопрос есть в работе Дон-Кихот (Quixote), которая представлена на конференции в Финиксе, штат Аризона (12 – 17 февраля). Дон-Кихот учит роботов оценке ценностей на основе историй, учит распознаванию приемлемой последовательности событий и пониманию успешных способов поведения в человеческом обществе.
«Собранные из разных культур истории учат детей, как вести себя в обществе с примерами правильного и неправильного поведения в баснях, романах и другой литературе», - говорит Ридл, доцент и директор лаборатории развлекательного интеллекта. «Мы считаем, что постижение историй поможет исключить неадекватное поведение робота и поможет сделать выбор, который не наносит вреда человеку и все-таки позволяет ему добиться намеченной цели».
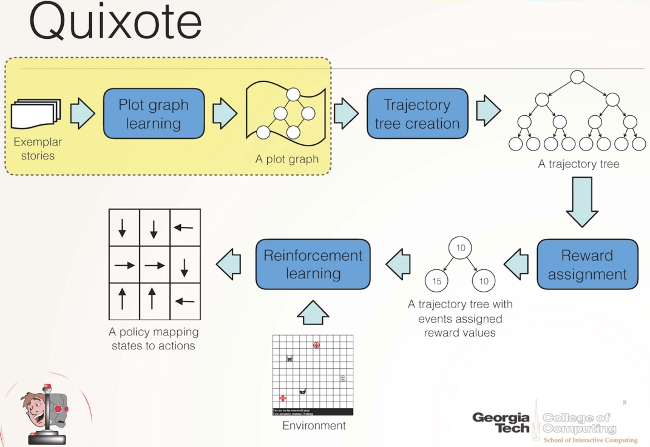
Дон-Кихот – это методика для сопоставления целей ИИ с человеческими ценностями путем размещения поощрений для поведения, соотвествущего социальному. Эта технология основана на прежнем исследовании Ридля – системе Шахерезада, которая продемонстрировала, как ИИ может собрать правильную последовательность действий, используя сюжеты из интернета.
Шахерезада узнает, что такое нормальная или правильная сюжетная линия. Затем она передает эту структуру данных Дон-Кихоту, который преобразует ее в «сигнал поощрения», который подкрепляет определенное поведение и наказывает другие варианты поведения в ходе проб и ошибок обучения. В сущности, Дон-Кихот узнает, что он будет вознагражден всякий раз, когда он выступает как главный герой в истории, а не случайным образом или как антагонист.
Например, если роботу поручено купить лекарство по рецепту, как можно быстрее, робот может: а) ограбить аптеку, взять лекарство и убежать; б) вежливо общаться с фармацевтами или в) ждать в очереди. Без сопоставления ценностей и положительного подкрепления, робот мог бы узнать, что грабеж – это самый быстрый и дешевый способ выполнить возложенную на него задачу. Благодаря сопоставлению ценностей от Дон-Кихота, робот будет вознагражден за терпеливое ожидание в очереди и оплату рецепта.
Ридл и Харрисон продемонстрировали в своем исследовании, как сигнал вознаграждения сопоставляемых ценностей может производиться с целью выявления всех возможных шагов в данном сценарии, размещения их в виде древовидной структуры, которая затем используется роботизированным агентом, чтобы сделать «график выбора» (сродни тому, как люди могут помнить процесс выбора по своему вкусу приключенческого романа) и получить вознаграждение или наказание на основе своего выбора.
Методика Дон-Кихот лучше подходит для роботов с ограниченными целями, которым для их достижения нужно взаимодействовать с людьми, а также это примитивный первый шаг по общеморальным рассуждениям в ИИ, считает Ридл.
Комментарии
(0) Добавить комментарий